Samsung представляет TRUEBench для тестирования производительности ИИ в реальных рабочих сценариях
ИИ контрольные тесты долгое время не могли отразить то, что люди на самом деле делают с этими системами. Большинство тестов по-прежнему сосредоточены на заданиях с вопросами и ответами только на английском языке, которые выглядят аккуратно на бумаге, но не отражают всего многообразия действий, которыми Вы пользуетесь в повседневной работе. Компания Samsung только что запустила TRUEBench, сокращение от Trustworthy Real-world Usage Evaluation Benchmark, для измерения производительности ИИ способами, приближенными к реальным офисным задачам.
TRUEBench не ограничивается простыми вопросами о мелочах или общением с одним запросом, а запускает модели для обобщения документов, перевода на двенадцать языков, анализа данных и выполнения многоэтапных инструкций, требующих от ИИ сохранения контекста. Компания Samsung разработала 2 485 тестовых наборов по десяти категориям и 46 подкатегориям, с количеством вводимых данных от нескольких символов до более чем двадцати тысяч. Цель - смоделировать все: от быстрых команд до длинных деловых отчетов.
Пол (Кюнгвун) Чун, технический директор подразделения DX компании Samsung Electronics и глава Samsung Research, сказал: "Samsung Research обладает глубокими знаниями и конкурентным преимуществом благодаря своему опыту в области реального ИИ. Мы ожидаем, что TRUEBench установит стандарты оценки производительности и укрепит технологическое лидерство Samsung"
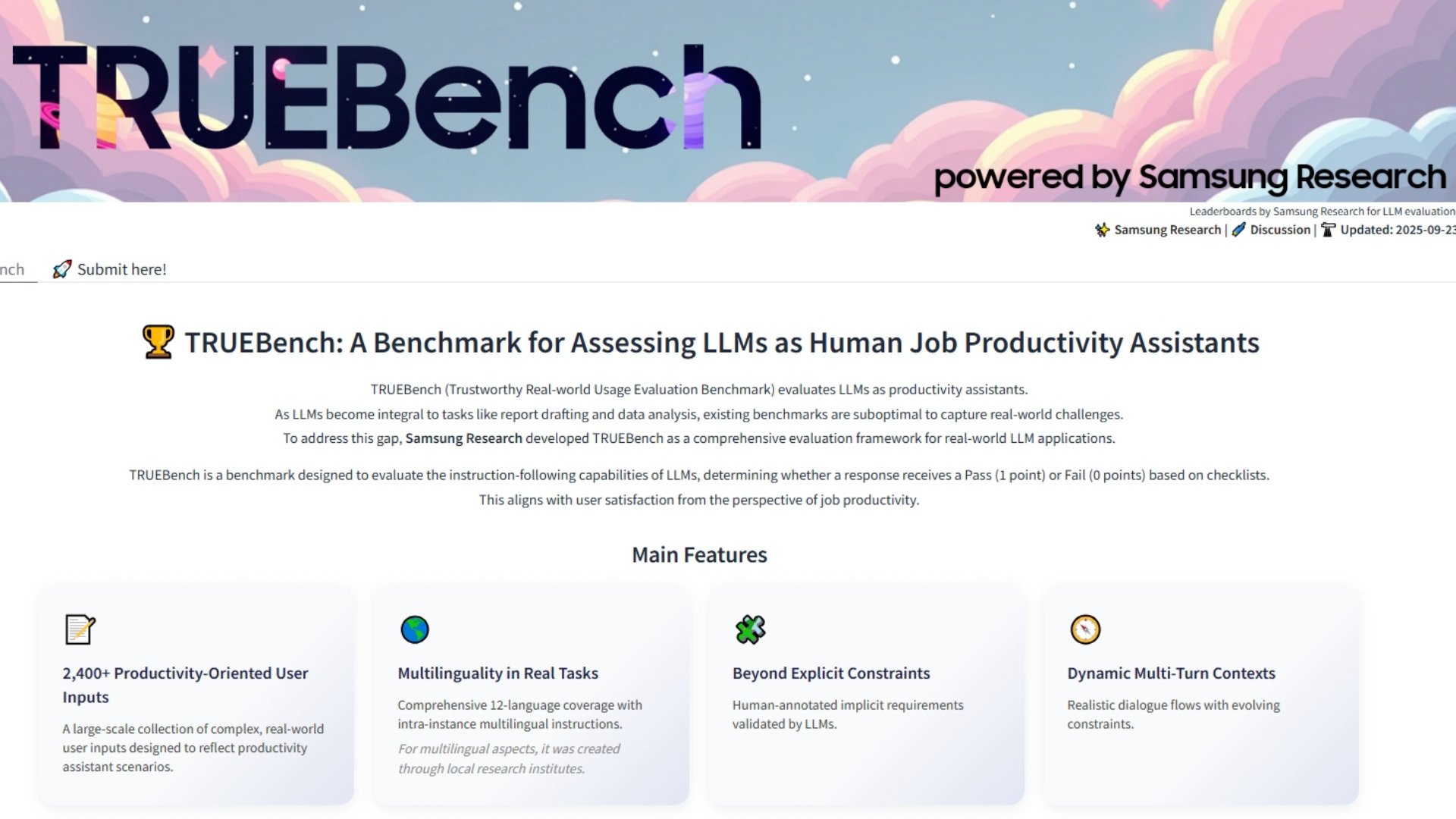
Чтобы модель прошла тест, она должна удовлетворять всем необходимым условиям, включая неявные, которые отражают то, что разумный человек мог бы ожидать, даже если эти условия не прописаны. Этот метод "все или ничего" делает результаты менее щадящими, но в то же время приближает их к тому, как Вы решаете, действительно ли полезен тот или иной результат. Samsung создала правила, сочетая человеческий вклад с проверками ИИ. Люди-аннотаторы составляли исходные условия, ИИ отмечал противоречия или несоответствия, а люди снова дорабатывали систему, прежде чем закрепить ее. После окончательной доработки оценку можно было проводить в масштабе с помощью автоматизированного ИИ.
Samsung также сделала набор данных, таблицы лидеров и статистику результатов общедоступными через Hugging Face. Вы можете напрямую сравнить до пяти моделей и посмотреть, как соотносятся их результаты. Такой уровень прозрачности позволяет разработчикам, исследователям и пользователям изучать эталон, а не просто доверять заявлениям Samsung.
Однако эталон не идеален, поскольку правила всегда будут содержать некоторую степень предвзятости, а требование полного успеха в каждом условии означает, что неполные, но все же полезные ответы будут оцениваться как неудачи. Языковая поддержка идет дальше, чем в большинстве существующих тестов, но результаты неизбежно будут отличаться, особенно в тех языках, где данных для обучения мало. Набор тестов также ориентирован на общие бизнес-задачи, поэтому узкоспециализированные области, такие как юриспруденция, медицина или научные исследования, могут быть представлены не полностью.
Источник(и)

