Этот удобный инструмент с открытым исходным кодом извлекает текст из чего угодно - даже из видео и изображений

Знакомая проблема? Большинство PDF-файлов позволяют Вам копировать текст без проблем. Но время от времени Вы сталкиваетесь с PDF, который явно не был создан из текстового документа - он был сгенерирован из отсканированных изображений, хотя его содержимое полностью состоит из текста. В таких случаях Вы не сможете ничего выделить или скопировать, если не воспользуетесь дополнительными инструментами. Это расстраивает.
Другой пример: Я смотрю видео о лучших RC-кроулерах (машинах с дистанционным управлением, созданных специально для преодоления пересеченной местности) в определенном ценовом диапазоне, потому что мой ребенок увлекается ими. Названия моделей показаны в видео, но их нигде нет в виде текста, который можно выбрать в описании.
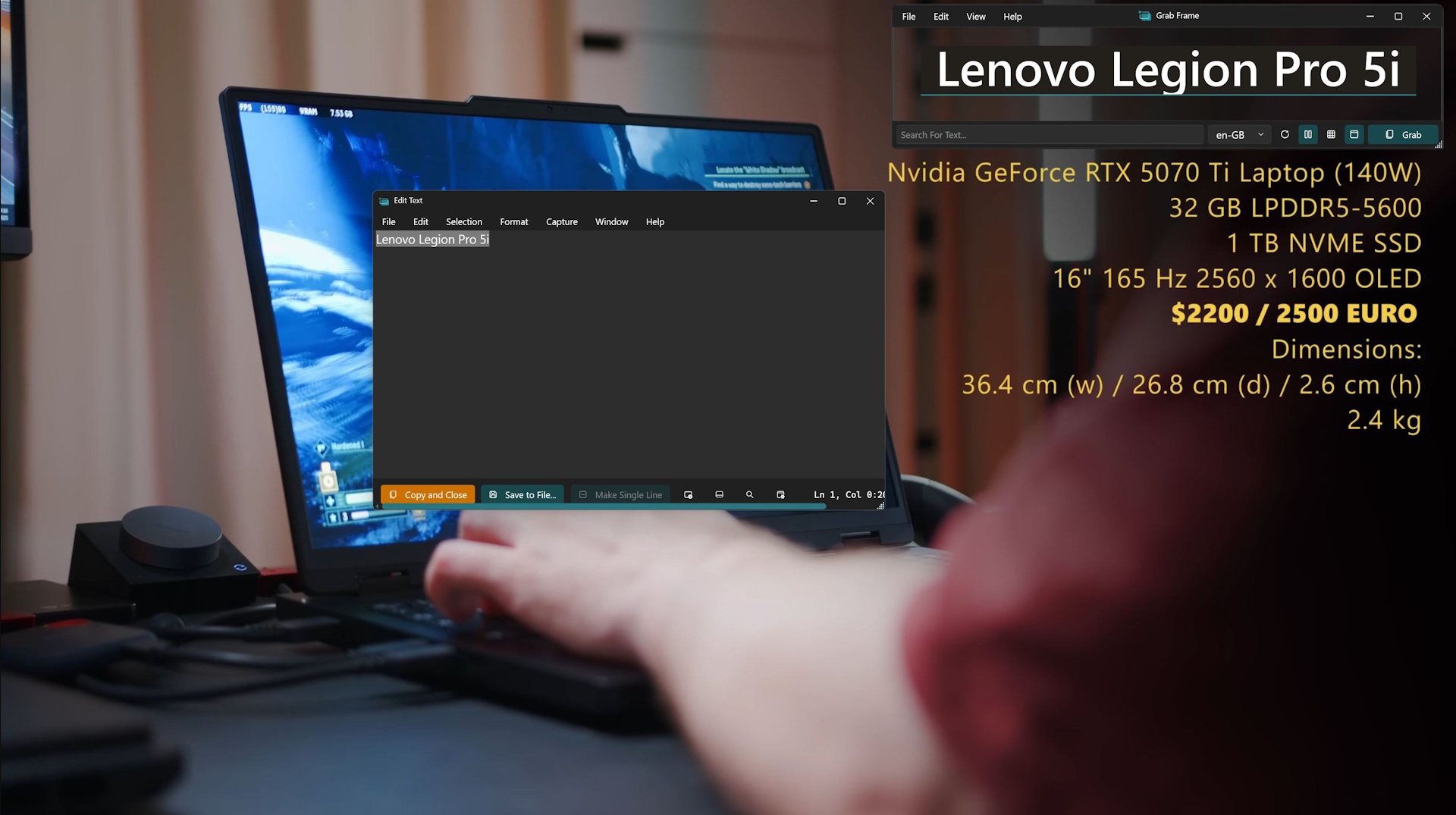
Именно здесь на помощь приходит Text Grab: Этот инструмент с открытым исходным кодом доступен на Github для ПК с Windows x86 и ARM64, и он делает именно то, что я хотел бы иметь в таких ситуациях: он извлекает текст из изображений, видео, PDF-файлов с фотографиями - в общем, из всего, что появляется на Вашем экране.
Использование приложения не может быть проще. Приложение работает как стандартный инструмент для создания скриншотов. Вы делаете снимок всего экрана или только выделенной области, а Text Grab немедленно распознает любой текст на этом изображении и копирует его в буфер обмена. Как и в других утилитах для создания скриншотов, Вы можете настроить собственные горячие клавиши для захвата всего экрана или определенных областей.
Несмотря на то, что размер приложения составляет всего 74 МБ, оно предлагает несколько способов захвата текста. Вы можете сканировать весь экран, нарисовать рамку вокруг меньшей области или даже щелкнуть прямо на отдельном слове. При желании инструмент может автоматически открыть Блокнот с извлеченным текстом, готовым к редактированию.
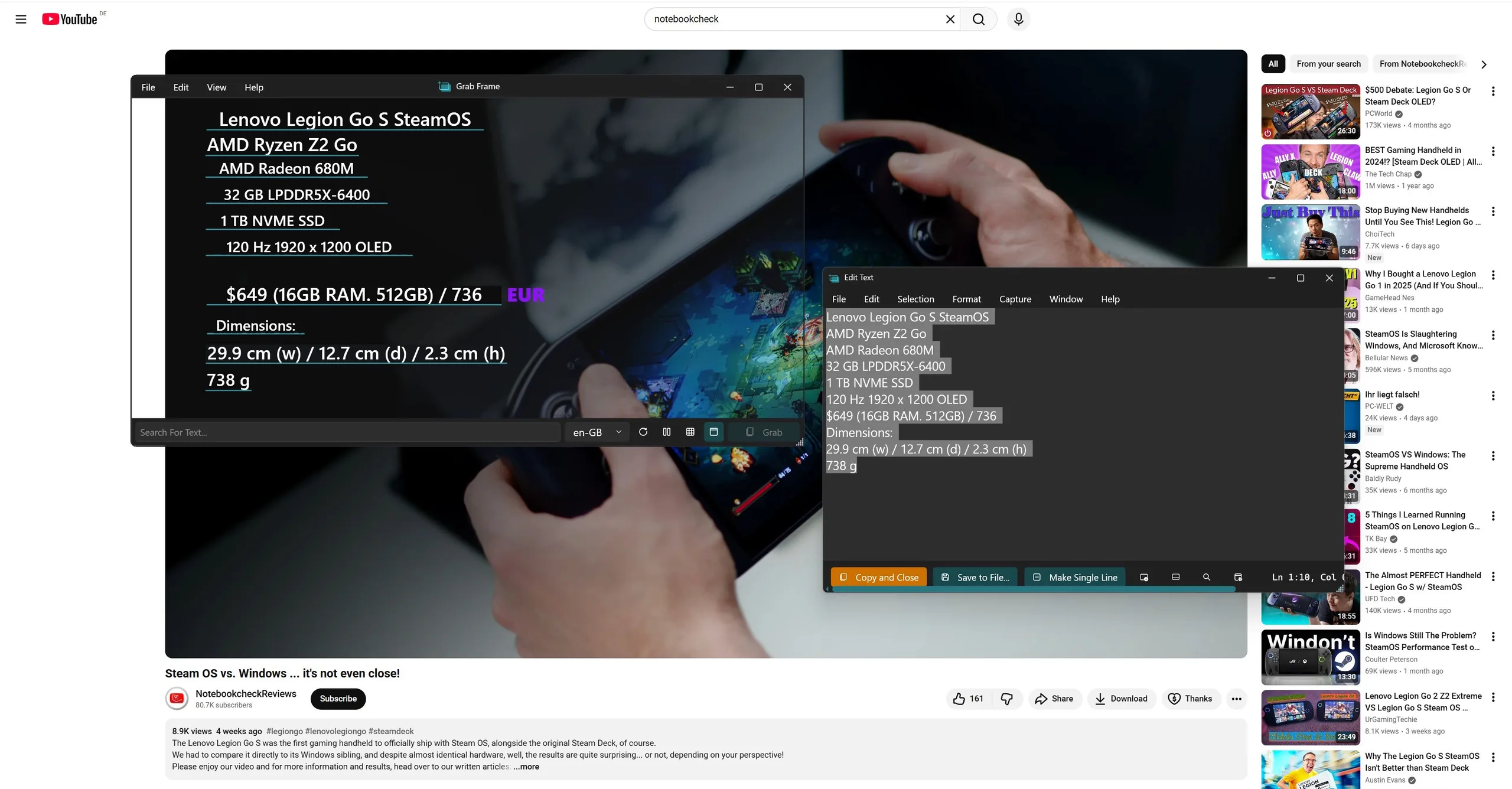
Как это работает: За кулисами приложение делает снимок экрана и отправляет его на механизм OCR (Optical Character Recognition - оптическое распознавание символов), встроенный в Windows API. Все выполняется локально.
Инструмент, как правило, очень точный, легкий и полностью с открытым исходным кодом. Однако он не идеален. У меня было несколько случаев, когда он неправильно читал что-то, но встроенный редактор, который появляется автоматически, позволяет легко внести быстрые исправления.

