Удивительный язык побеждает английский и китайский в тестах на получение степени магистра, согласно новому академическому исследованию
Новое многоязычное исследование, в котором оценивается, как большие языковые модели справляются с длинными документами, дало неожиданную информацию: Польский язык, а не английский или китайский, показывает наивысшую точность, когда контекстные окна растягиваются до 64 000 лексем и более. Выводы были сделаны на основе эталона OneRuler, представленного в документе COLM 2025в котором тестировались 26 языков в задачах поиска и агрегирования.
Исследователи сравнили точность модели при различной длине контекста и обнаружили явный сдвиг, когда последовательности становились длиннее. Согласно таблице результатов (на странице 6), польский язык лидирует среди всех языков со средней точностью 88% при длинных контекстах. Английский опустился на шестое место, а китайский оказался в четверке лучших.
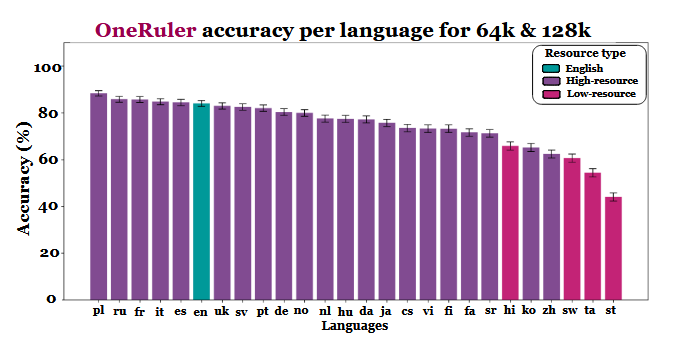
Исследование намекает на то, что различия могут быть связаны с эффективностью токенизации и различиями в системах письма, а не просто с объемом обучающих данных. Языки, использующие латинскую письменность - такие как польский, французский и испанский - неизменно демонстрировали лучшие результаты, чем языки, использующие логографическую или абугидную системы письма. Китайский, корейский, тамильский и другие языки показали лишь умеренную точность даже в коротких контекстах (и их точность ухудшалась еще больше, когда последовательности становились длиннее). Такое полное несоответствие ожидаемому рейтингу интересно, поскольку большинство широко используемых LLM обучаются в основном на наборах данных с высоким содержанием английского языка. Однако результаты, полученные в статье, указывают на то, что когда модели должны искать, вспоминать или обобщать информацию, запрятанную глубоко в длинных документах, структурные аспекты языка оказываются предпочтительнее, чем распространенность набора данных.
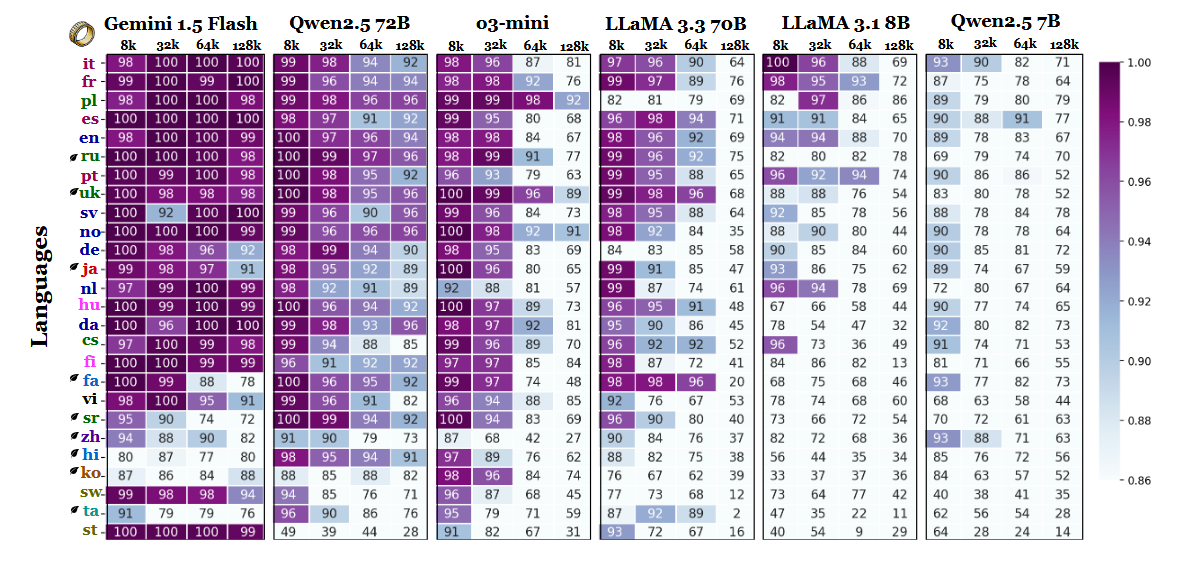
Другие результаты эталонного тестирования также подтверждают эту интерпретацию. Разрыв в производительности между самыми сильными и самыми слабыми языками резко увеличивается по мере расширения контекста - с 11% при 8 000 лексем до 34% при 128 000 лексем. Еще одна деталь исследования показывает, насколько чувствительными могут быть эти тесты к небольшим изменениям в инструкции. Например, простое разрешение модели отвечать "нет", если целевая строка отсутствует, привело к тому, что точность в английском языке упала на 32% при 128 000 лексем, как показано на странице 2.
Хотя в бенчмарке также сравниваются семейства моделей, полученные результаты говорят о том, что при оценке длинных контекстов нельзя полагаться только на тестирование на английском языке и что обобщения производительности по языкам могут вводить в заблуждение, если игнорировать эффекты скриптов и токенизации. По мере увеличения контекстных окон языковые различия становятся все более важными, а не менее - и доминирование английского языка в эталонных тестах LLM может перестать быть репрезентативным, когда длина последовательности перевалит за десятки тысяч.
Источник(и)

