CheckMag | Нет GPU - нет проблем. Разместить свой собственный LLM - это бесконечно веселее, чем цензурные предложения от крупных игроков, и работает на удивление хорошо.

Что на самом деле происходит с Вашими данными, когда Вы запрашиваете их у искусственного интеллекта, можно только догадываться, но что бы с ними ни случилось, они уже точно не Ваши.
Наряду с изображения и видео, если Вы хотите поэкспериментировать с большими языковыми моделями (LLM), но не хотите передавать свои данные крупным технологиям, создать свою собственную - удивительно просто и имеет ряд преимуществ перед крупными игроками.
Прежде всего, что бы Вы ни решили с ним делать, все Ваши данные остаются под Вашим контролем, что, если Вы не хотите передавать свои данные Mechahitlerявляется несомненным плюсом. Вы также можете использовать практически любую модель, которая Вам нравится, будь то Deepseek, Gemma2 или GPT, с дополнительным преимуществом в том, что Вы можете использовать версии, которые не ограничивают типы запросов, которые Вы в них вводите.
KoboldCPP - это простой в использовании, одноисполняемый инструмент для генерации текстов ИИ, предназначенный для запуска больших языковых моделей GGUF и GGML. Он поддерживает как GPU, так и CPU и может выступать в качестве специализированного бэкэнда для ИИ-рассказов и чата. KoboldCPP можно загрузить с GitHub здесь и доступен для Windows, Linux, Mac или Docker.
Размещение в контейнере позволяет легко подключить LLM к любому устройству в Вашей сети, а для основных платформ, включая Unraid и TrueNAS, существуют готовые шаблоны. То же самое можно сделать и с другими установками, если Вы добавите необходимые правила в свой брандмауэр.
Начало работы
Как только Вы определитесь с выбором платформы, Вам нужно будет решить, какую модель использовать. Hugging Face лучшее место для поиска моделей, и они должны быть в формате GGUF.
Если Вы планируете проводить сценарии D&D, Вам определенно нужна модель без цензуры, иначе LLM в конечном итоге откажется причинять вред персонажам и может привести к нежелательным результатам результаты.
Некоторые модели, такие как Deepseek и Claudeимеют склонность к "думанию", что, по сути, выплескивает весь мыслительный процесс Вашего запроса. Это может быть нормально при наличии графического процессора, выполняющего тяжелую работу, но без него процесс значительно замедляется. Вам придется поэкспериментировать с моделями, чтобы найти ту, которая подойдет именно Вам, но Gemma2 это хорошее место для начала.
Найдите страницу с файлами и скопируйте URL, который ссылается на файл GGUF. Многие модели имеют несколько размеров, поэтому Вам нужно будет выбрать ту, которая вписывается в ограничения Вашей доступной оперативной памяти.
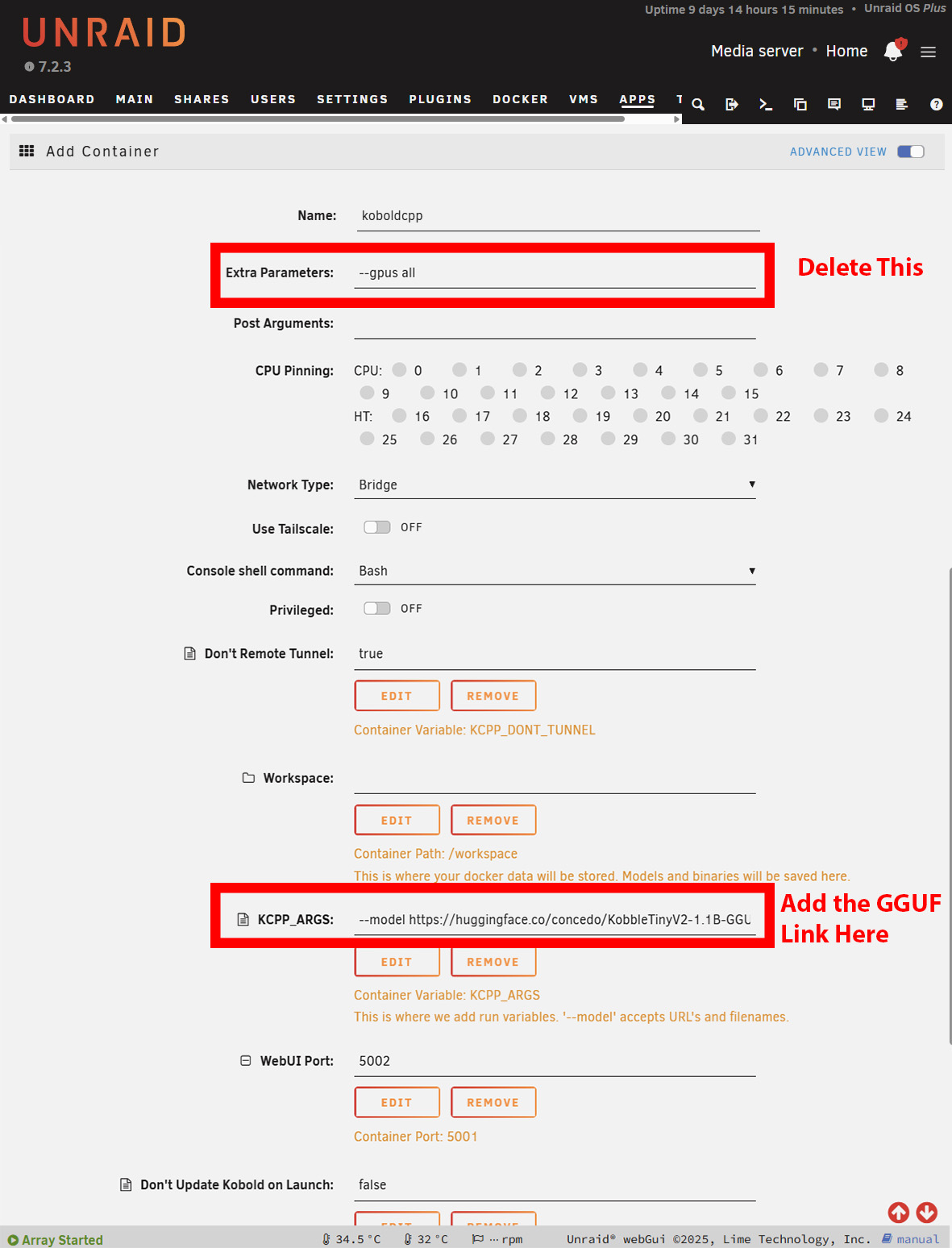
Установка под Windows во многом аналогична. Однако Вам нужно будет загрузить NoCUDA если Вы работаете без GPU. Запуск может занять некоторое время, поскольку KoboldCPP загрузит модель, прежде чем представить Вам интерфейс. На Windows это очевидно, но на Unraid или TrueNAS Вам придется открыть журналы, чтобы увидеть прогресс загрузки. На Unraid Вам может понадобиться увеличить доступное хранилище для контейнеров Docker в зависимости от того, насколько велика выбранная Вами модель.
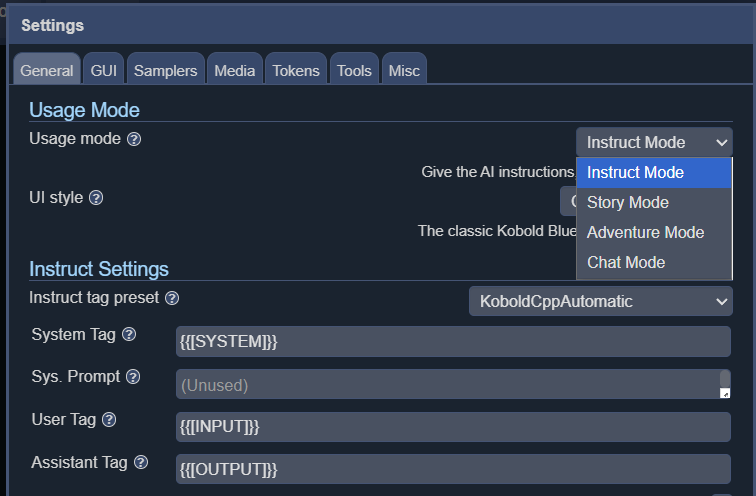
KoboldCPP предлагает 4 различных режима интерфейса, включая инструктаж, сюжет, чат и приключения.
Несмотря на то, что игра не самая быстрая, текст генерируется немного медленнее, чем средняя скорость чтения. Вполне пригоден для сценариев D&D при работе на 16-ядерном AMD 5950x(доступен на Amazon) и, вероятно, будет работать быстрее на более современных процессорах. Чем больше ядер Вы сможете задействовать, тем лучше, а приличный объем оперативной памяти позволит Вам запускать более крупные модели, хотя Вам будет достаточно и 16 Гб. Размер и тип модели также окажут значительное влияние на скорость генерации, и выбор более легкой модели может значительно увеличить общую скорость.
Очевидно, что для получения наилучших впечатлений оптимально запускать Большие языковые модели с помощью GPU, однако, если Вы хотите попробовать разместить свои собственные модели, минуя ограничения или последствия конфиденциальности данных ChatGPT, Claude или Gemini, Вам не потребуется никакого модного оборудования, чтобы начать работу, и Вы все равно сможете получить достойный опыт.
Источник(и)

